
|
|
|
|
|
|
|
|
|
|
|
| [Paper] | [Code] | [Data] | [Bibtex] |
|
|
|
Humans excel in complex long-horizon soft body manipulation tasks via flexible tool use: bread baking requires a knife to slice the dough and a rolling pin to flatten it. Often regarded as a hallmark of human cognition, tool use in autonomous robots remains limited due to challenges in understanding tool-object interactions. Here we develop an intelligent robotic system, RoboCook, which perceives, models, and manipulates elasto-plastic objects with various tools. RoboCook uses point cloud scene representations, models tool-object interactions with Graph Neural Networks (GNNs), and combines tool classification with self-supervised policy learning to devise manipulation plans. We demonstrate that from just 20 minutes of real-world interaction data per tool, a general-purpose robot arm can learn complex long-horizon soft object manipulation tasks, such as making dumplings and alphabet letter cookies. Extensive evaluations show that RoboCook substantially outperforms state-of-the-art approaches, exhibits robustness against severe external disturbances, and demonstrates adaptability to different materials. |
|
Video 1: This video shows the results of making a dumpling and alphabet letter cookies with the RoboCook framework. |
|
Video 2: This video demonstrates the robustness of the RoboCook framework by applying external human perturbations during real-time execution. The highlight happens at 01:43. The human messes everything up and puts the excess dough back into a very irregular shape. The robot starts again from the beginning, demonstrating the robustness of the RoboCook framework in the face of heavy disturbance. |
|
Video 3: The video presents a failure mode of the RoboCook framework when making a dumpling. |
|
Video 4: The video presents the data collection process to train the dynamics model in the RoboCook framework. |
|
Video 5: The video shows the complete process of two human subjects making dumplings. |
|
|
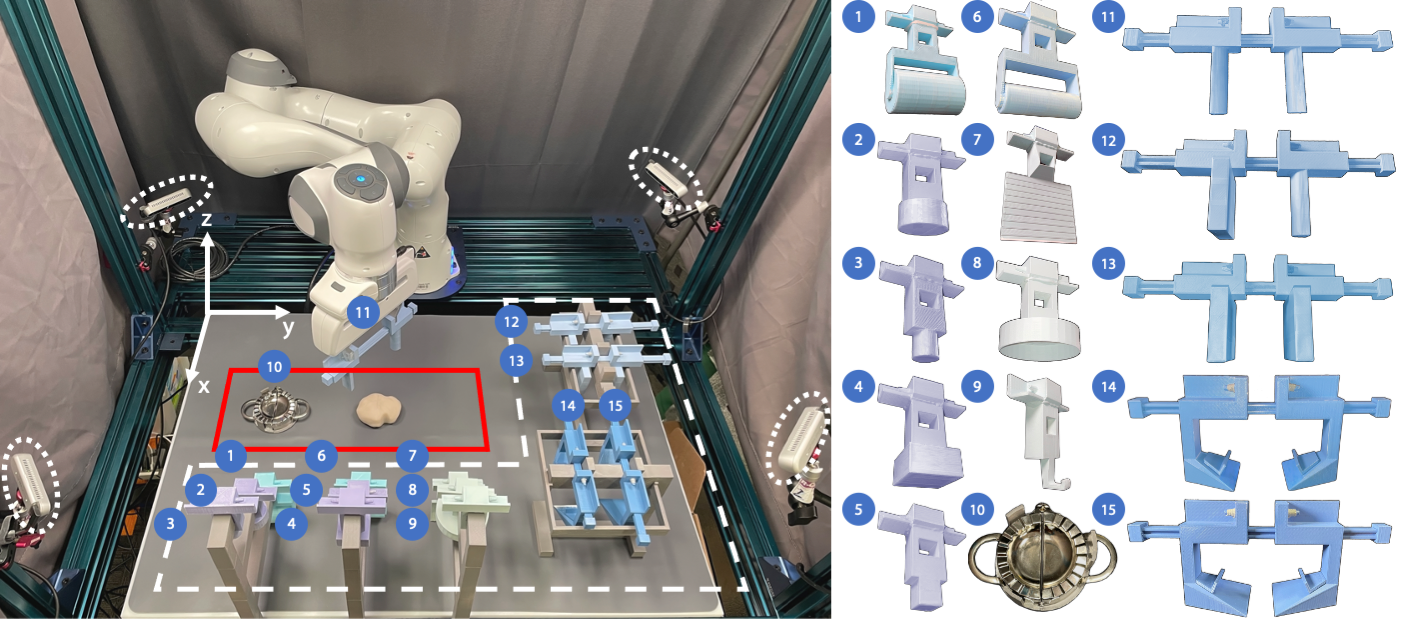
RoboCook hardware and setup: Left: Robot's tabletop workspace with xyz coordinates at top-left. Dashed white circles: four RGB-D cameras mounted at four corners of the table. Red square: dough location and manipulation area. Dashed white square: tool racks. Right: 15 tools: (1) large roller, (2) circle press, (3) circle punch, (4) square press, (5) square punch, (6) small roller, (7) knife/pusher, (8) circle cutter, (9) hook, (10) dumpling mold, (11) two-rod symmetric gripper, (12) asymmetric gripper, (13) two-plane symmetric gripper, (14) skin spatula, (15) filling spatula.Tools are 3D-printed, representing common dough manipulation tools. The supplementary materials in the paper discusses the design principles of these 3D-printed tools. |
|
|
|
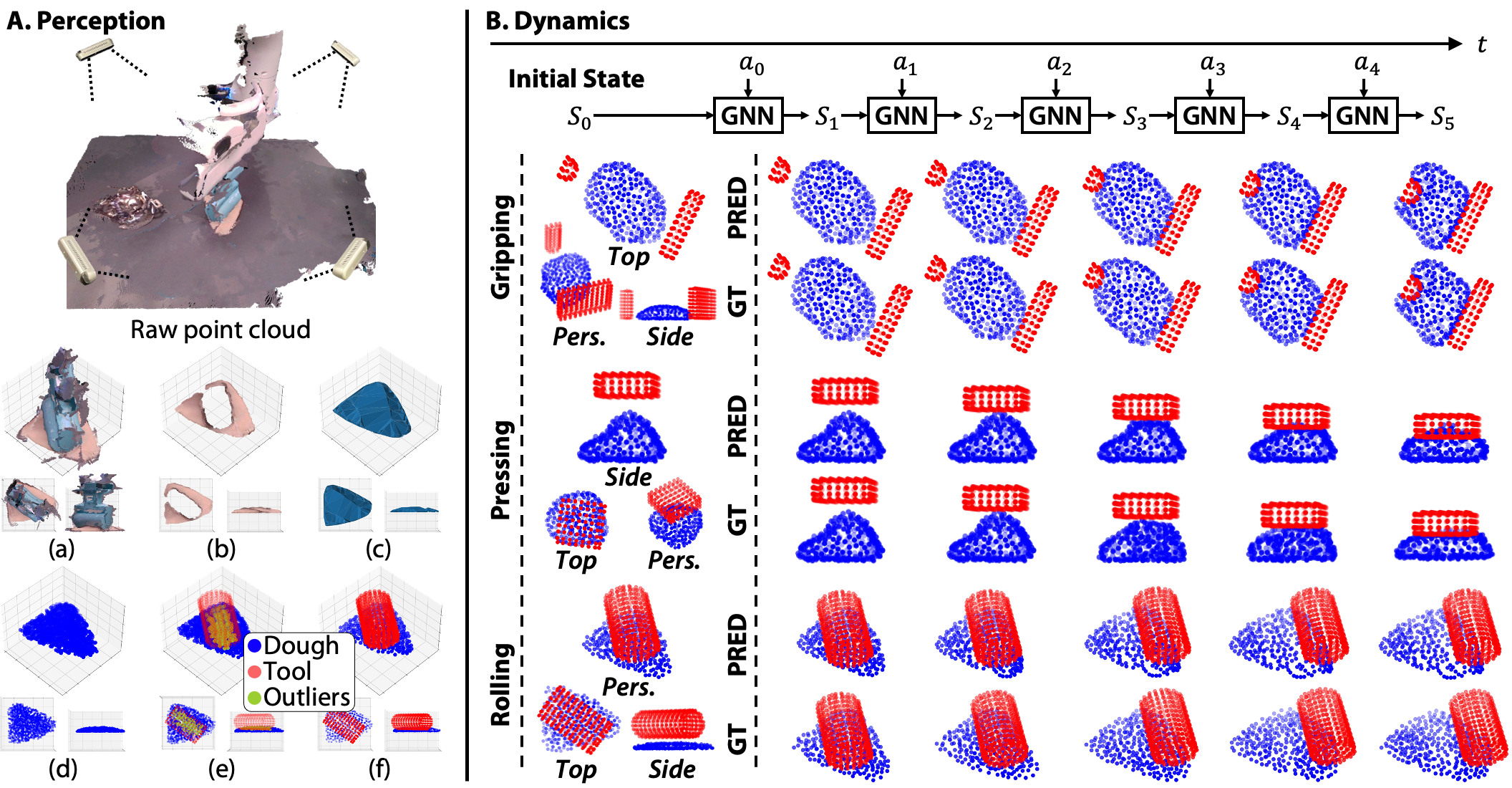
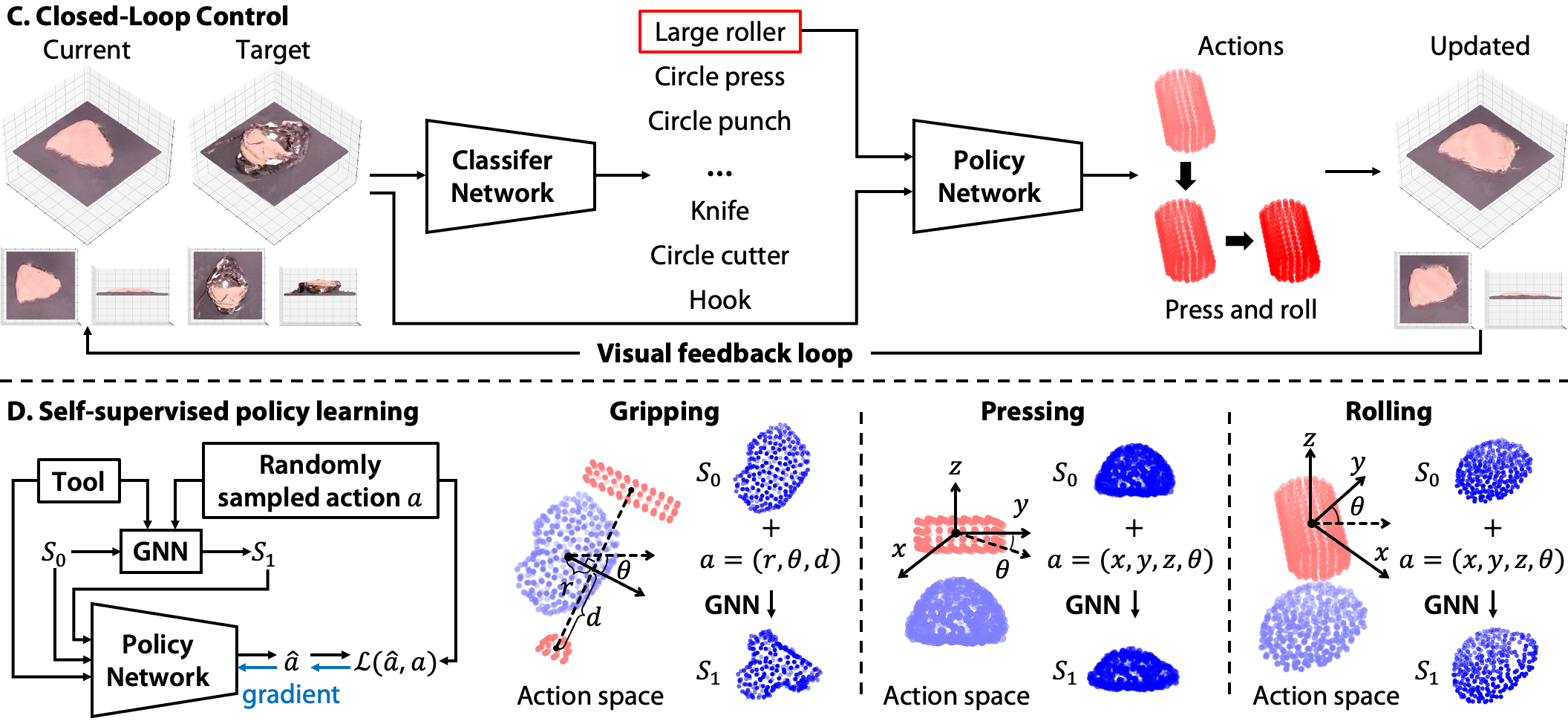
(A) Perception: The input to the perception module is a point cloud of the robot’s workspace captured by four RGB-D cameras. From the raw point cloud, we (a) crop the region of interest, (b) extract the dough point cloud, (c) reconstruct a watertight mesh (d) use the Signed Distance Function (SDF) to sample points inside the mesh, (e) remove points within the tools' SDF, and (f) sample 300 surface points. (B) Dynamics: We process videos of each tool manipulating the dough into a particle trajectory dataset to train our GNN-based dynamics model. The model can accurately predict long-horizon state changes of the dough in gripping, pressing, and rolling tasks. On the left are the initial states' perspective, top, and side views, and on the right is a comparison of model predictions and ground truth states. (C) Closed-loop control: PointNet-based classifier network identifies appropriate tools based on the current observation and the target dough configuration. The self-supervised policy network takes the tool class, the current observation, and the target dough configuration as inputs and outputs the manipulation actions. The framework closes the control loop with visual feedback. (D) Self-supervised policy learning: We show the policy network architecture, the parametrized action spaces of gripping, pressing, and rolling, and how we generate the synthetic datasets to train the policy network. |
|
|
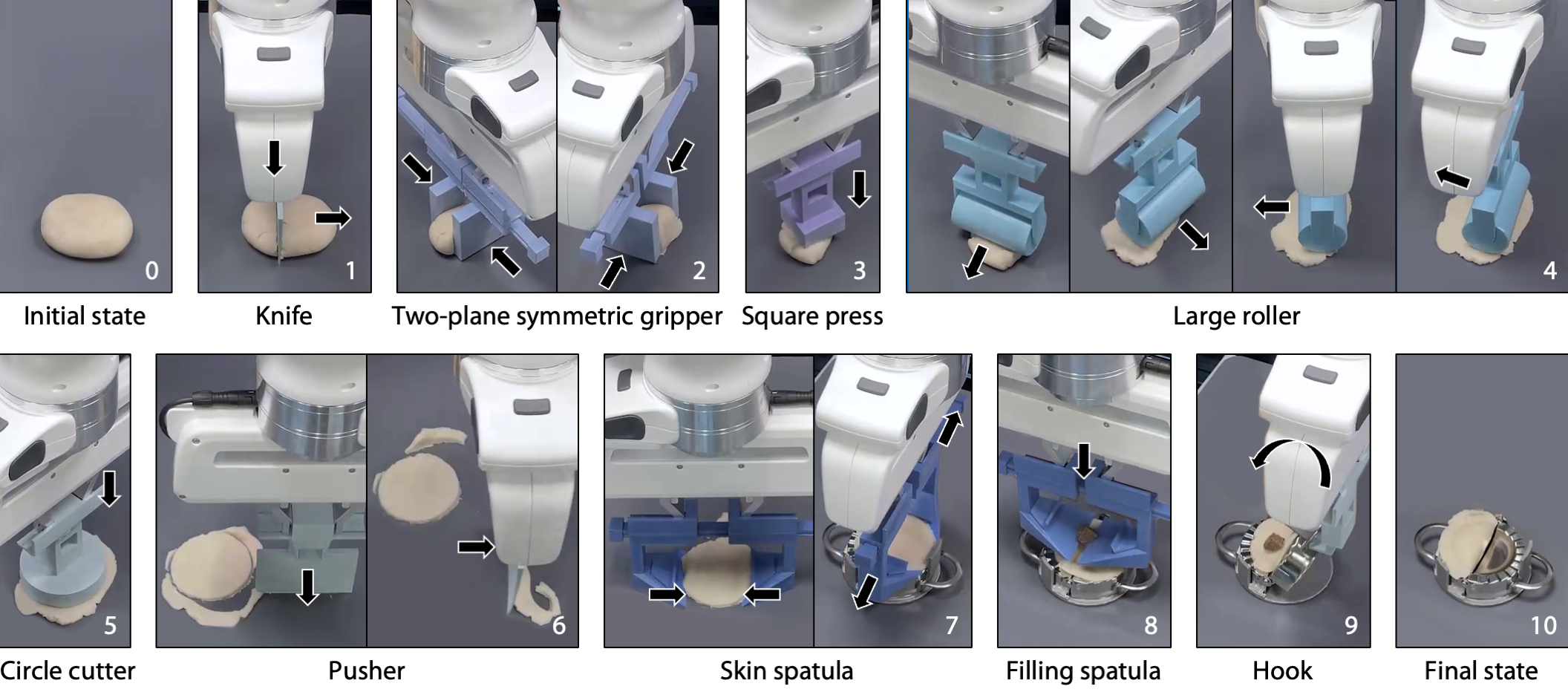
Making Dumplings: RoboCook makes a dumpling from a piece of dough in nine steps: The robot (1) cuts the dough to an appropriate volume, (2) pinches the dough and regularizes the shape, (3) presses to flatten the dough, (4) rolls to flatten the dough further, (5) cuts a circular dumpling skin, (6) removes the excess dough, (7) picks and places the skin onto the mold, (8) adds the filling, and (9) closes and opens the mold. The black arrows denote the moving direction. |

|
|
Comparison with human subjects: We show a comparison with the manipulation results of human subjects. In the first row, Human subjects devise their manipulation plan and choose tools independently. In the second row, human subjects follow a given tool sequence and subgoals. |

|
|
Making alphabetical letter cookies: We list R, O, B, C, and K shaping steps in Columns 1 to 4. Column 5 manually highlights the contour of the alphabetical letters. Columns 6 through 9 compare our self-supervised learned policy with three model-based planning baselines and one RL baseline. Our method can shape the dough closer to the target than all four baseline methods. |

|
|
Quantitative evaluations: We use CD and EMD between the point clouds and the CD between the surface normals to evaluate the results. In addition to these geometrical metrics, we also ask humans to evaluate the results and compute their predicted accuracy and rank for each method averaged over the five letters. We further profile how long these methods take to plan actions. Our method outperforms all baseline methods in these metrics by a large margin. |
|
|
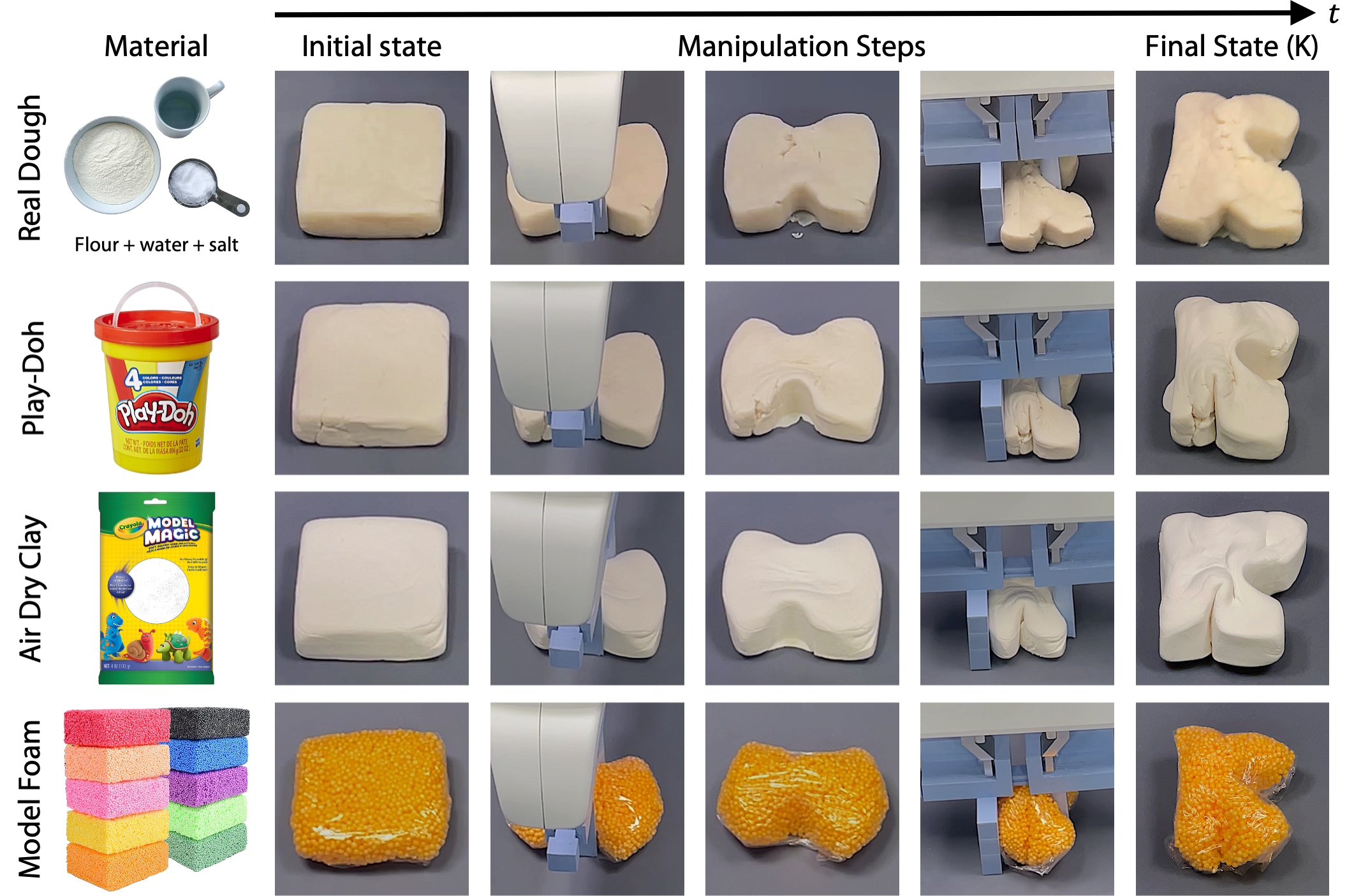
Generalizing to different materials: We showcase the dynamics model's capability to generalize to various materials by shaping a K without retraining. |
|
Acknowledgements |